Transformer
Introduction
In this post, I will be trying to understand the original Transformer paper.
Tokenization
Tokenization is the process of transforming words into a standardized input. In natural languages, a lot of words can be in a non-standard form (prefixes, suffixes, conjugation), and tokenization converts as many as possible of existing words into a limited dictionary.
Embedding
Embedding is the process of transforming tokens into vectors of floats. The reason this is useful is that we can capture semantic relationships between individual tokens by transforming them to vectors. In theory, the shorter the distance between vectors, the closer they should be semantically. The embeddings are often used pre-trained which means someone else already trained a network that explicitly produces an embedding for a token (e.g. Word2Vec, GloVe, BERT).
For a lot of natural language tasks, a position of the token in the overall input is also very important. In order to capture that, the Transformer’s input needs to also consider the positional information of the token. In the original Transformer, they used a separate positional embedding vector that is based on trigonometric functions. This positional embedding vector is then just summed with the token embedding to produce the final input embedding for the Transformer.
Attention
Attention is the mechanism through which Transformers are able to extract contextual information from the input. Francois Chollet described it succinctly: “The purpose of self-attention is to modulate the representation of a token by using the representations of related tokens in the sequence.” (F. Chollet, p. 338)
The attention layer in the Transformer case is basically doing a dot product between input embeddings and then using the results to weight how much individual tokens are related to each other.
See this snapshot from Chollet’s book:
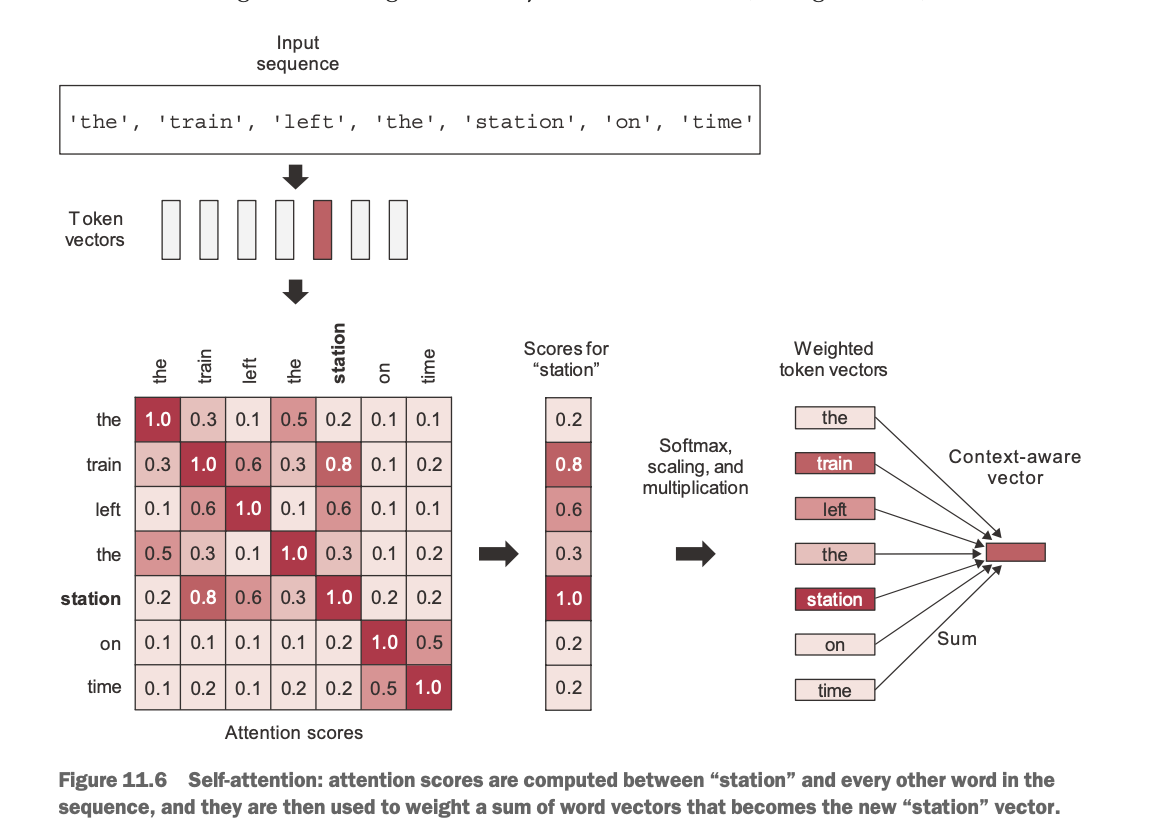
In addition, in the Transformer case they use separate learned matrices to weight input attention vectors. This is similar to learned kernels in convolutional networks and its purpose is to enable learning of more complex features in the attention blocks of the network. To even enhance the process of learning complex semantic relationships, the authors introduce using multiple attention heads in parallel (in addition to using them in successive layers). To be honest, here I have the biggest gap as I have a hard time understanding how the transformer is able to capture such a diverse range of relationships between different grammatical structures (verbs, direct/indirect objects, etc.) in sequences that differ so much. But I guess this is the magic of generalization (and can be compared to how convolutional networks can learn to recognize objects regardless of their shape, size, or position in the input image).
There is one more feature that is necessary to ensure that during inference only past tokens influence the current prediction. Authors use masked attention where they basically mask out (set to a special value) all the future tokens during the process of learning.
Encoder & Decoder
Encoders and decoders are the highest-level architectural components of the Transformer. Both of them are composed of multiple blocks of attention and feed-forward layers. Encoder’s output is primarily an internal representation of input embeddings, while decoder’s output is output probabilities across the dictionary (i.e. the next token prediction).
The purpose of these layers is succinctly described in the Wiki article: “The function of each encoder layer is to generate contextualized token representations, where each representation corresponds to a token that “mixes” information from other input tokens via self-attention mechanism. Each decoder layer contains two attention sublayers: (1) cross-attention for incorporating the output of encoder (contextualized input token representations), and (2) self-attention for “mixing” information among the input tokens to the decoder (i.e., the tokens generated so far during inference time).”
The original architecture was primarily intended for language translation tasks and uses both an encoder and a decoder component. However, these pieces are quite independent. For example, GPT models are decoder-only, while BERT models are encoder-only. This depends on the final objective (next token prediction in the original language, embeddings, language translation, etc…)
Full architecture
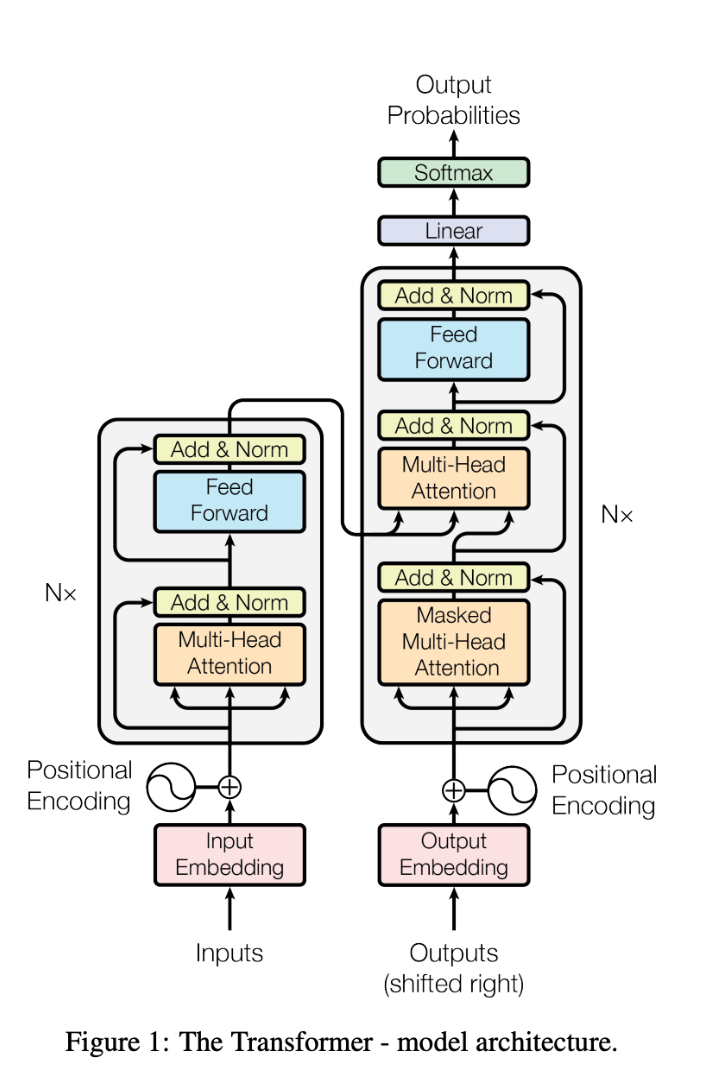
At this point, we should be able to understand this architectural graph from the original paper. Input text is passed into the first layer to produce input embeddings with positional information baked in. Then the encoder is composed of several iterations of attention and feed-forward layers.
The decoder part starts with the output embeddings (enhanced with positional information) and continues with a stack of multiple core blocks containing masked attention to the output embeddings, attention to the result of the encoder, and a feed-forward layer. The output of the decoder block is then passed into a linear layer and we obtain the next token prediction by running a softmax against its output.
Sources:
- Francois Chollet: Deep Learning with Python
- https://tinkerd.net/blog/machine-learning/bert-tokenization/
- https://tinkerd.net/blog/machine-learning/bert-embeddings/
- https://phontron.com/class/anlp2024/assets/slides/anlp-05-transformers.pdf
- https://nlp.seas.harvard.edu/2018/04/03/attention.html
- https://jalammar.github.io/illustrated-transformer
- https://docs.google.com/presentation/d/1ZXFIhYczos679r70Yu8vV9uO6B1J0ztzeDxbnBxD1S0/edit#slide=id.g31364026ad_3_2